To Russia With Love¶
Using PycURL¶
Say it's 1982, the height of the Cold War, and you're a journalist doing a piece on how the Internet looks from behind the Iron Curtain. Ignoring the minor detail that the Internet doesn't yet exist, we'll walk you through how you could do it - no passport required!
The Internet isn't uniform. Localization, censorship, and selective service based on your IP's geographic location can make the Internet a very different place depending on where you're coming from.
Tor relays are scattered all over the world and, as such, you can pretend to be from any place running an exit. This can be especially useful to evade pesky geolocational restrictions, such as news sites that refuse to work while you're traveling abroad.
Tor makes configuring your exit locale easy through the ExitNodes torrc option. Note that you don't need a control port (or even Stem) to do this, though they can be useful if you later want to do something more elaborate.
In the following example we're using Stem to start Tor, then read a site through it with PycURL. This is not always reliable (some relays are lemons) so you may need to run this more than once.
Having an issue? The following are some common gotchas...
- PycURL's PROXYTYPE_SOCKS5_HOSTNAME was added in v7.19.5.1. Try upgrading if you get an AttributeError about it.
- The following example for exiting through Russia will only work if... well, the Tor network has a Russian exit. Often this isn't the case. If Tor fails to bootstrap try dropping the line with 'ExitNodes': '{ru}'.
Do not rely on the following not to leak. Though it seems to work there may be edge cases that expose your real IP. If you have a suggestion for how to improve this example then please let me know!
import io
import pycurl
import stem.process
from stem.util import term
SOCKS_PORT = 7000
def query(url):
"""
Uses pycurl to fetch a site using the proxy on the SOCKS_PORT.
"""
output = io.BytesIO()
query = pycurl.Curl()
query.setopt(pycurl.URL, url)
query.setopt(pycurl.PROXY, 'localhost')
query.setopt(pycurl.PROXYPORT, SOCKS_PORT)
query.setopt(pycurl.PROXYTYPE, pycurl.PROXYTYPE_SOCKS5_HOSTNAME)
query.setopt(pycurl.WRITEFUNCTION, output.write)
try:
query.perform()
return output.getvalue()
except pycurl.error as exc:
return "Unable to reach %s (%s)" % (url, exc)
# Start an instance of Tor configured to only exit through Russia. This prints
# Tor's bootstrap information as it starts. Note that this likely will not
# work if you have another Tor instance running.
def print_bootstrap_lines(line):
if "Bootstrapped " in line:
print(term.format(line, term.Color.BLUE))
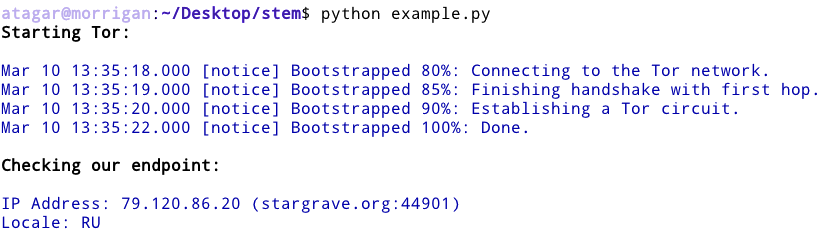
print(term.format("Starting Tor:\n", term.Attr.BOLD))
tor_process = stem.process.launch_tor_with_config(
config = {
'SocksPort': str(SOCKS_PORT),
'ExitNodes': '{ru}',
},
init_msg_handler = print_bootstrap_lines,
)
print(term.format("\nChecking our endpoint:\n", term.Attr.BOLD))
print(term.format(query("https://www.atagar.com/echo.php"), term.Color.BLUE))
tor_process.kill() # stops tor
Using SocksiPy¶
Besides PycURL, you can also use SocksiPy to do the same. Be aware that the following example routes all socket connections through Tor, so this'll break our ability to connect to Tor's control port. To use this approach simply replace the query() function above with...
import socks # SocksiPy module
import socket
import urllib
SOCKS_PORT = 7000
# Set socks proxy and wrap the urllib module
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, '127.0.0.1', SOCKS_PORT)
socket.socket = socks.socksocket
# Perform DNS resolution through the socket
def getaddrinfo(*args):
return [(socket.AF_INET, socket.SOCK_STREAM, 6, '', (args[0], args[1]))]
socket.getaddrinfo = getaddrinfo
def query(url):
"""
Uses urllib to fetch a site using SocksiPy for Tor over the SOCKS_PORT.
"""
try:
return urllib.urlopen(url).read()
except:
return "Unable to reach %s" % url
Reading Twitter¶
Now lets do something a little more interesting, and read a Twitter feed over Tor. This can be done using their API, for authentication see their instructions...
import binascii
import hashlib
import hmac
import json
import socket
import time
import urllib
import urllib2
import socks # SockiPy module
import stem.process
SOCKS_PORT = 7000
TWITTER_API_URL = "https://api.twitter.com/1.1/statuses/user_timeline.json"
CONSUMER_KEY = ""
CONSUMER_SECRET = ""
ACCESS_TOKEN = ""
ACCESS_TOKEN_SECRET = ""
HEADER_AUTH_KEYS = ['oauth_consumer_key', 'oauth_nonce', 'oauth_signature',
'oauth_signature_method', 'oauth_timestamp', 'oauth_token', 'oauth_version']
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, '127.0.0.1', SOCKS_PORT)
socket.socket = socks.socksocket
def oauth_signature(key_dict):
fin_key = ""
for key in sorted(key_dict.keys()):
fin_key += key + "=" + key_dict[key] + "&"
fin_key = fin_key[:-1]
fin_key = 'GET' + "&" + urllib.quote(TWITTER_API_URL, '') + "&" + urllib.quote(fin_key, '')
key = urllib.quote(CONSUMER_SECRET, '') + "&" + urllib.quote(ACCESS_TOKEN_SECRET, '')
hashed = hmac.new(key, fin_key, hashlib.sha1)
fin_key = binascii.b2a_base64(hashed.digest())[:-1]
return urllib.quote(fin_key, '')
def poll_twitter_feed(user_id, tweet_count):
"""
Polls Twitter for the tweets from a given user.
"""
key_dict = {
'oauth_consumer_key': urllib.quote(CONSUMER_KEY, ''),
'oauth_nonce': urllib.quote(hashlib.md5(str(time.time())).hexdigest(), ''),
'oauth_signature_method': urllib.quote("HMAC-SHA1", ''),
'oauth_timestamp': urllib.quote(str(int(time.time())), ''),
'oauth_token': urllib.quote(ACCESS_TOKEN, ''),
'oauth_version': urllib.quote('1.0', ''),
}
url_values = {'screen_name': user_id, 'count': str(tweet_count), 'include_rts': '1'}
for key, value in url_values.items():
key_dict[key] = urllib.quote(value, '')
key_dict['oauth_signature'] = oauth_signature(key_dict)
header_auth = 'OAuth ' + ', '.join(['%s="%s"' % (key, key_dict[key]) for key in HEADER_AUTH_KEYS])
data = urllib.urlencode(url_values)
api_request = urllib2.Request(TWITTER_API_URL + "?" + data, headers = {'Authorization': header_auth})
try:
api_response = urllib2.urlopen(api_request).read()
except:
raise IOError("Unable to reach %s" % TWITTER_API_URL)
return json.loads(api_response)
tor_process = stem.process.launch_tor_with_config(
config = {
'SocksPort': str(SOCKS_PORT),
'ExitNodes': '{ru}',
},
)
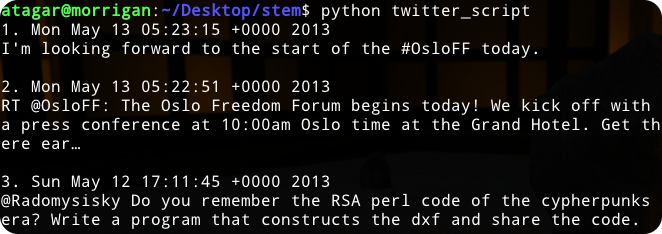
try:
for index, tweet in enumerate(poll_twitter_feed('ioerror', 3)):
print("%i. %s" % (index + 1, tweet["created_at"]))
print(tweet["text"])
print("")
except IOError as exc:
print(exc)
finally:
tor_process.kill() # stops tor
Custom Path Selection¶
Routing requests over Tor is all well and good, but what if you want to do something more sophisticated? Through Tor's controller interface you can manage your own circuits and streams.
A circuit is your path through the Tor network. Circuits must consist of at least two relays, and must end with a relay that allows connections to the destination you want to reach.
Streams by contrast are TCP connections carried over a circuit. Tor handles attaching streams to a circuit that can service it. To instead manage this yourself call...
controller.set_conf('__LeaveStreamsUnattached', '1')
For an example of this lets fetch a site over each relay to determine it's reachability and speed. Naturally doing this causes quite a bit of load so please be careful not to leave this running!
import StringIO
import time
import pycurl
import stem.control
# Static exit for us to make 2-hop circuits through. Picking aurora, a
# particularly beefy one...
#
# https://metrics.torproject.org/rs.html#details/379FB450010D17078B3766C2273303C358C3A442
EXIT_FINGERPRINT = '379FB450010D17078B3766C2273303C358C3A442'
SOCKS_PORT = 9050
CONNECTION_TIMEOUT = 30 # timeout before we give up on a circuit
def query(url):
"""
Uses pycurl to fetch a site using the proxy on the SOCKS_PORT.
"""
output = StringIO.StringIO()
query = pycurl.Curl()
query.setopt(pycurl.URL, url)
query.setopt(pycurl.PROXY, 'localhost')
query.setopt(pycurl.PROXYPORT, SOCKS_PORT)
query.setopt(pycurl.PROXYTYPE, pycurl.PROXYTYPE_SOCKS5_HOSTNAME)
query.setopt(pycurl.CONNECTTIMEOUT, CONNECTION_TIMEOUT)
query.setopt(pycurl.WRITEFUNCTION, output.write)
try:
query.perform()
return output.getvalue()
except pycurl.error as exc:
raise ValueError("Unable to reach %s (%s)" % (url, exc))
def scan(controller, path):
"""
Fetch check.torproject.org through the given path of relays, providing back
the time it took.
"""
circuit_id = controller.new_circuit(path, await_build = True)
def attach_stream(stream):
if stream.status == 'NEW':
controller.attach_stream(stream.id, circuit_id)
controller.add_event_listener(attach_stream, stem.control.EventType.STREAM)
try:
controller.set_conf('__LeaveStreamsUnattached', '1') # leave stream management to us
start_time = time.time()
check_page = query('https://check.torproject.org/')
if 'Congratulations. This browser is configured to use Tor.' not in check_page:
raise ValueError("Request didn't have the right content")
return time.time() - start_time
finally:
controller.remove_event_listener(attach_stream)
controller.reset_conf('__LeaveStreamsUnattached')
with stem.control.Controller.from_port() as controller:
controller.authenticate()
relay_fingerprints = [desc.fingerprint for desc in controller.get_network_statuses()]
for fingerprint in relay_fingerprints:
try:
time_taken = scan(controller, [fingerprint, EXIT_FINGERPRINT])
print('%s => %0.2f seconds' % (fingerprint, time_taken))
except Exception as exc:
print('%s => %s' % (fingerprint, exc))
% python scan_network.py
000050888CF58A50E824E534063FF71A762CB227 => 2.62 seconds
000149E6EF7102AACA9690D6E8DD2932124B94AB => 2.50 seconds
000A10D43011EA4928A35F610405F92B4433B4DC => 2.18 seconds
000F18AC2CDAE4C710BA0898DC9E21E72E0117D8 => 2.40 seconds
0011BD2485AD45D984EC4159C88FC066E5E3300E => 2.03 seconds
003000C32D9E16FCCAEFD89336467C01E16FB00D => 11.41 seconds
008E9B9D7FF523CE1C5026B480E0127E64FA7A19 => 2.24 seconds
009851DF933754B00DDE876FCE4088CE1B4940C1 => 2.39 seconds
0098C475875ABC4AA864738B1D1079F711C38287 => Unable to reach https://check.torproject.org/ ((28, 'SSL connection timeout'))
00B70D1F261EBF4576D06CE0DA69E1F700598239 => 2.41 seconds
00DFA1137D178EE012B96F64D12F03B4D69CA0B2 => 4.53 seconds
00EF4569C8E4E165286DE6D293DCCE1BB1F280F7 => Circuit failed to be created: CHANNEL_CLOSED
00F12AB035D62C919A1F37C2A67144F17ACC9E75 => 3.58 seconds
00F2D93EBAF2F51D6EE4DCB0F37D91D72F824B16 => 2.12 seconds
00FCFBC5770DC6B716D917C73A0DE722CCF2DFE5 => 2.16 seconds
...